As Stage 2 of the JISC #coursedata programme http://www.jisc.ac.uk/whatwedo/programmes/elearning/coursedata.aspx enters it’s final stages we will be starting to look at the project outputs.
One requirement is the production of :
a system generated XCRI-CAP 1.2 feed with a cool URI for institutional course provision, especially part time, online/distance, post graduate and CPD.
But what does that actually mean? I thought it would useful to share with the wider world the feed acceptance criteria we are using in the programme.
“…a system generated…” feed is one that is automatically output from an institutions coursedata processes – importantly it needs to be something that actually takes effort to stop – Whilst it’s entirely possible to hand-craft an artisanal xml feed, that’s not what is wanted here.
“…XCRI-CAP1.2 feed…”
The feed needs to be valid and adhere to XCRI-CAP 1.2 specification http://www.xcri.org/wiki/index.php/XCRI_CAP_1.2
The eXchanging Course Related Iinformation – Course Advertising Profile (XCRI-CAP) is a specification to enable the interoperability of descriptions of courses, or any other kind of learning opportunity, between the course provider and any number of Aggregators and brokers, by supplying an XML description.
XCRI-CAP 1.2 provides an XML format based on the CEN Metadata for Learning Opportunities standard BS EN 15982, which means documents that conform to this specification have the same underlying semantics as those produced to other bindings of the same standard.
XCRI-CAP 1.2 itself has been standardised as BS 8581 -1 & 2
To check whether a feed meets the specification we have an online #coursedata validator which can be found at http://validator.xcri.co.uk/.
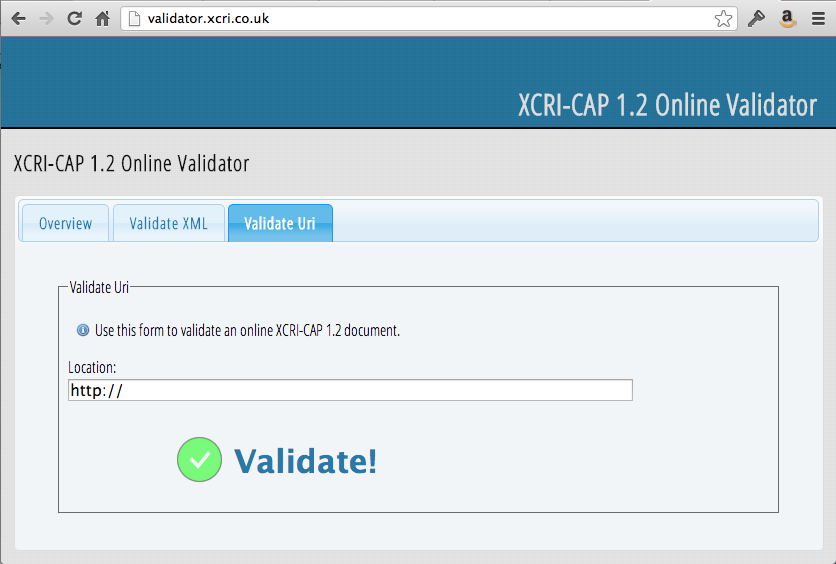
The Validator is very simple to use – select the ‘validate URI’ tab, and paste a feed address into the Location field. If the feed is exceptionally large it may timeout on the validator, and in this instance it may be necessary to run a local instance of the validator.
We consider a valid feed to be one without “Exceptions” and preferably without “Warnings” although it is acceptable to have “Recommendation” issues.
There are instances where it may be difficult not to incur “Warnings” :
(1) those requiring cross-element content checking that the validator cannot carry out, for example a Warning is generated if a course doesn’t have a qualification, although in many cases this is entirely correct (CPD for example)
(2) some elements are Preferred, but in some cases data is simply unavailable or not relevant – for example ‘all presentations should contain an attendancePattern’, but distance learning courses don’t have attendance, so attendancePattern is not relevant.
(3) In addition a few elements have character limits and exceeding these generates a Warning (for example Abstract at 140 characters and the large text elements at 4,000) it should be noted that aggregators *may* truncate these entries.
“…with a cool URI…” basically an address that isn’t going to change, that is easy to find because it sits in a sensible common location such as:
data.foo.ac.uk/courses.xml
foo.ac.uk/data/courses.xml
foo.ac.uk/courses.xml
Information on minting a cool URI can be found from the Lincoln Toolkit:
http://lncn.eu/toolkit
http://linkingyou.blogs.lincoln.ac.uk/2011/04/19/all-recommendations-lead-back-to-cool-uris/
The feed should have a clear and open licence, normally we’d specify something like the Creative Commons licence, but that has a problem if it indicates attribution, as it can lead to a “attribution stacking” where each of the licences in an aggregated feed have to co-exist.
Detailed guidance on licencing is available from the data definitions Document section 34-36: http://www.xcri.co.uk/data-definitions-and-vocabulary-framework.html
“It is suggested a OGL (Open Government licence) is used, and recorded in the in the description element of the catalog element:
• Name of the licence, for example ‘Open Government Licence (OGL)’
• Version number of the licence
• Owner of the licence, for example ‘University of Test’”
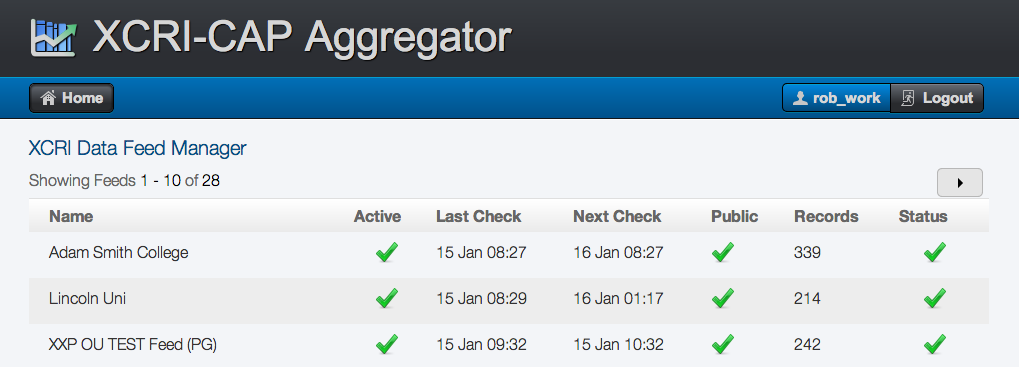
Finally so we can track the feeds, they need to be registered in the JISC feed Aggregator, and when ready make it public.
http://coursedata.k-int.com/FeedManager/
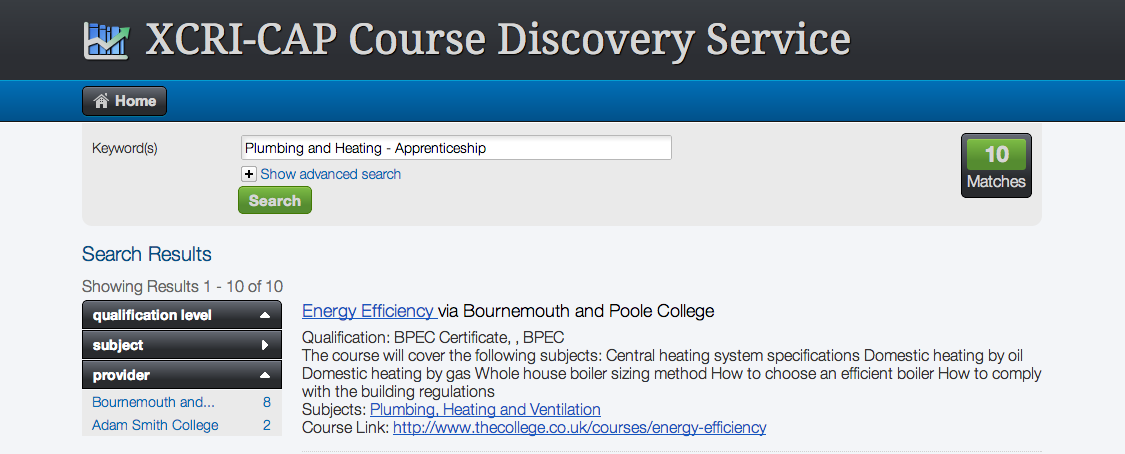
Once the feed is public it can be searched through the JISC Aggregator discovery service http://coursedata.k-int.com/discover/, or its API – https://github.com/k-int/XCRI-Aggregator/wiki
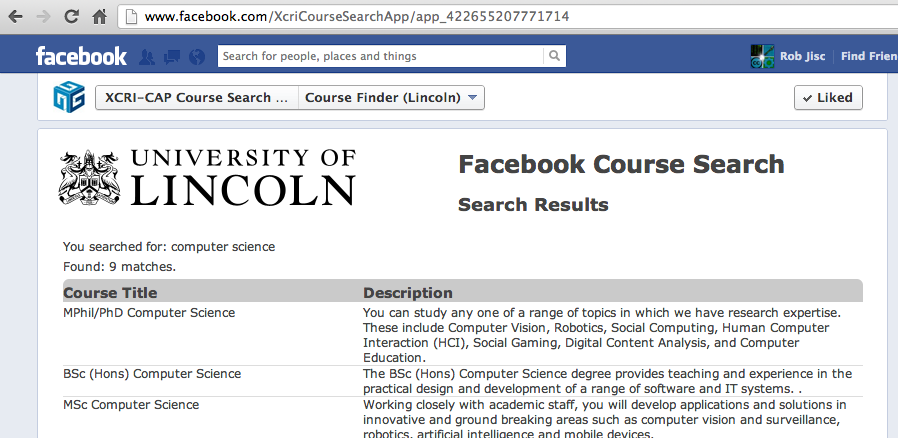
We have a number of demonstration applications that draw data from the Aggregator to show potential uses of feeds.
http://www.jisc.ac.uk/whatwedo/programmes/elearning/coursedata/demonstrators.aspx
Such as the the facebook course search app, which can be adapted and embedded in an institutional facebook site, and provide course search functionality.
http://www.facebook.com/XcriCourseSearchApp
One reply on “#coursedata – Feed acceptance”
[…] outputs produce an xcri-cap feed. I’ve talked a bit about the feed acceptance criteria in an earlier post but didn’t really expand on why you’d want to produce an xcri-cap feed.. or what […]